

📈 #84 Where did the time go? Part V: hardware (Part A)
Does faster computation mean faster optimization?

In February 2019, I started working for Fujitsu for solving optimization problems with their quantum-inspired hardware, Digital Annealer.
I did it because of the quantum word, I cannot lie here. But also because of the team and the project I was going to start working on. I could see with my own eyes the improvements that a specialized hardware can give you.
But the rest of the optimization industry was attached to traditional processors.
However, AI researchers, that solve optimization problems every single day to train their neural networks, migrated to GPUs, and quantum startups (and not-so-startups) promise revolutionary speedups.
So the crucial question here was: are we missing out on massive performance gains, or is there something fundamentally different about optimization that keeps us tethered to CPUs?
This is a complex issue, so I’ve splitted into two, and today’s Feasible article will explore why we’ve been stuck with CPUs.
In the next ones, we’ll see what faster hardware is on the shell and what can we do with all of that extra computational power.
Remember this is the fifth part of a 6-part series of posts focused on tractability. We started with bencharking before fixing, then large-scale problems, three more parts centered on symmetries (what they mean and classical techniques, more advanced techniques, and ML-guided techniques and practical ways to dealing with symmetries), and finally algorithms and parallelization.
Ready? Let’s dive in… 🪂

🤔 Why we’ve been stuck with CPUs
Let’s see why and the limits of that in 3 steps.
🎯 CPUs are taylor-made for optimization work
Modern MILP, CP-SAT, and Simplex loops mix fine-grained arithmetic with branch-heavy "if/else" logic.
Pivot selection, incumbent checks, cut callbacks.
And x86 and ARM server CPUs are built for exactly that pattern.
At the heart of any branch-and-bound algorithm we have something like:
if (current_bound < best_known_solution) {
explore_left_branch();
explore_right_branch();
} else {
prune_this_subtree();
}Modern CPUs include sophisticated branch predictors that guess which way these if statements will go. Modern branch predictors achieve 95%+ branch prediction accuracy1, keeping the pipeline full even when every iteration takes a different code path.
When your optimization algorithm reaches that branch-and-bound decision point, the CPU has already started executing the most likely path.
This is called speculative execution.
Also, you need to take into account the irregular memory access patterns from optimization algorithms. Consider the exploration of a search tree like this:
Node* current = root;
while (!current->is_leaf()) {
if (should_go_left(current)) {
current = current->left_child; // Memory address X
} else {
current = current->right_child; // Memory address Y
}
}The CPU has no idea which memory location will be accessed next, and these addresses might be scattered across RAM with no pattern.
CPUs dedicate enormous die area to cache memory, often more than 50% of the chip2, specifically to handle this irregular access. Cache hit rates of 85-95% are common for well-structured optimization algorithms.
Specialized accelerators typically sacrifice cache for more compute units, assuming predictable data access patterns that optimization algorithms rarely provide.
When talking about numerical stability and exact constraint satisfaction, optimization algorithms need the 64-bit precision of CPUs. Small rounding errors accumulate quickly and can lead to incorrect pivot selections, obtaining infeasible solutions declared as optimal ones.
Not only that, optimization problems often live in discrete worlds: assign Truck 1 to Route A or Route B, schedule Job 1 in time slot 3 or time slot 4. CPUs include fast 64-bit integer and bit-manipulation instructions, crucial for binary variables and node-status masks.
On top of all of this, the entire commercial solver ecosystem is hand-tuned for the CPU cache hierarchy, and cloud VM pricing/licensing is still quoted "per vCPU," not per GPU or qubit.
Decades of CPU-specific optimizations in solver code mean that even equivalent hardware might perform worse due to software maturity differences.
In short: CPUs + optimization have grown up together.
But…
🌪️ There are workloads that break the “CPU only” rule
However, there are specific cases where the algorithm characteristics change, and the CPU's branch advantage matters less.
When the heavy lifting collapses into large, regular math blocks, specialized hardware can actually help.
And when does that happen?
We’ve seen in previous articles part of the answer to this question. In particular, we’ve seen how Interior-Point Methods are easily parallelizable, making the irregular branching patterns disappear and being replaced by predictable linear algebra operations.
Also, Google’s PDLP was designed such that GPUs can take advantage of it.
Moreover, Digital Annealer from Fuijtsu and the like eliminate branches altogether by hard-wiring the update rule, encoding the problem directly in silicon and avoiding CPU’s general-purpose overhead entirely.
These are corner cases, but they prove accelerators can help when the algorithm sheds its irregular control flow.
💥 CPUs are hitting their own ceilings
Even loyal CPU users like me feel the squeeze from three fundamental walls that have plateaued CPU progress:
#1 The memory wall3
A modern 64-core CPU can theoretically demand data at rates that would saturate any memory system, as memory bandwith didn’t grow as fast as CPU core counts.
You can take a look at this chart that compares FLOPS vs Bandwidth, and how bandwidth didn’t grow as fast as FLOPS in Nvidia settings:
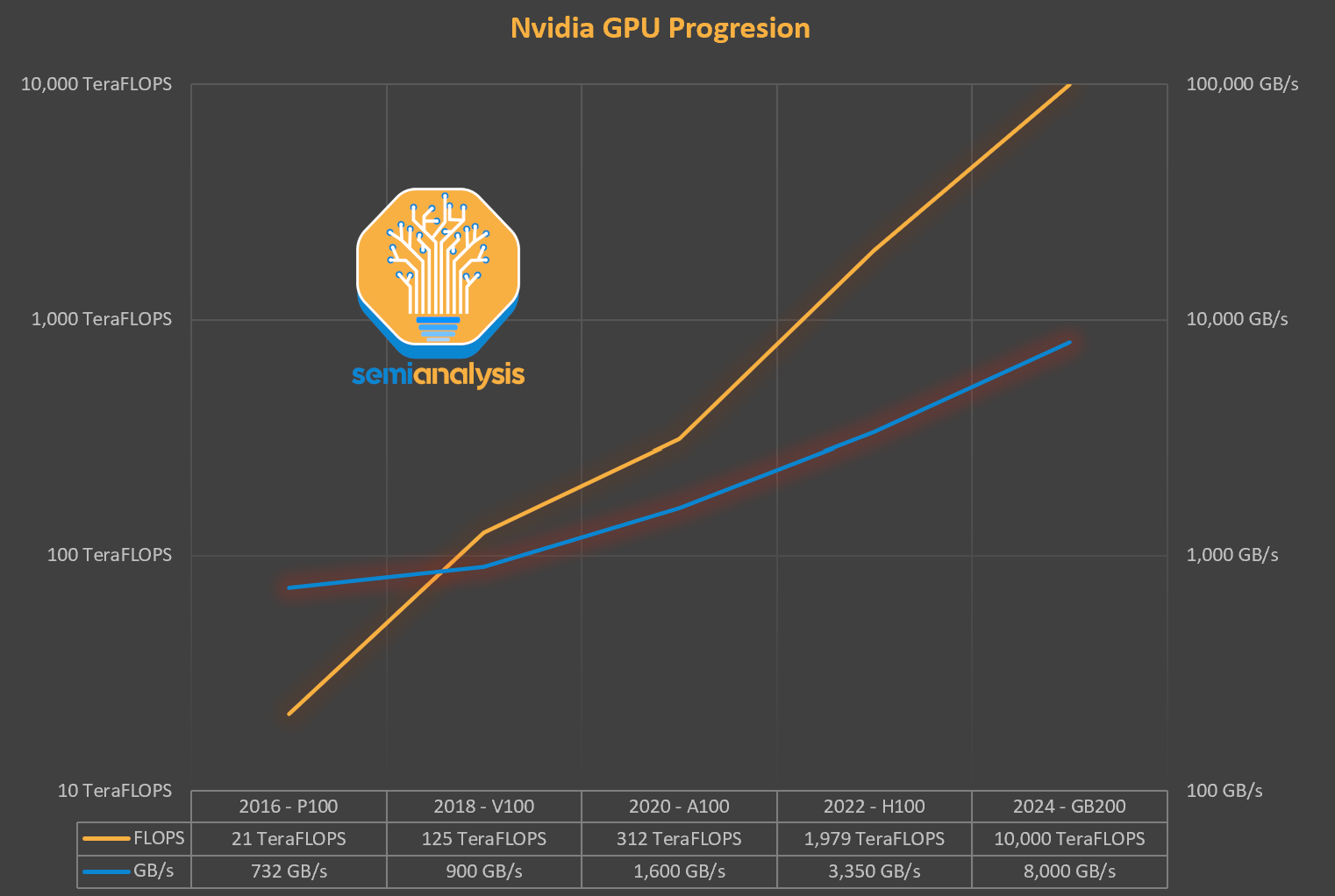
For instance, a dual-socket Intel Sapphire Rapids system tops out around 350 GB/s of memory bandwidth. Beyond 8-12 active cores, a branch-and-bound run spends most cycles stalled on cache misses, not computing solutions.
This is why throwing a 128-core machine at your optimization problem often performs worse than a 16-core machine with faster memory.
#2 The ILP wall
Out-of-order and speculative execution gains have flat-lined. Instructions per cycle (IPC) hasn't risen meaningfully since ~2015. CPU designers have largely maxed out their ability to find instruction-level parallelism in sequential code4.
When your algorithm is fundamentally "do A, then B, then C," there's only so much the CPU can parallelize at the instruction level.
#3 The power wall
Clock frequency has plateaued near 3-4 GHz because higher speeds outrun air-cooling budgets. Physics limits how much power you can dissipate from a small chip, and we hit that limit around 20055.
Instead of 8 GHz single cores, we got 4 GHz multi-cores. But optimization algorithms often can't use those extra cores effectively, so we traded single-thread performance (which optimization loves) for multi-thread capability (which optimization struggles to use in some cases).
Extra sockets therefore deliver diminishing returns, especially on memory-intensive Simplex and branch-and-bound workloads.
So if CPUs are hitting fundamental limits, and some optimization workloads don't fit the traditional CPU mold perfectly, what alternatives do we have?
The hardware landscape offers several intriguing possibilities: from quantum computers promising exponential speedups to GPUs that revolutionized AI.
But do they actually work for optimization? Next week, we'll explore what's really available and when (if ever) you should consider alternatives to your trusty CPU.
Let’s keep optimizing,
Borja.
🗞️ Other related posts people like




Slides about Moore’s Law (look at the figure in slide 6)