

📈 #93 I vibe-coded an OR agent (and it worked)
A tiny experiment that turned into a glimpse of how AI agents might reshape how we code -and how we think- in Operations Research.

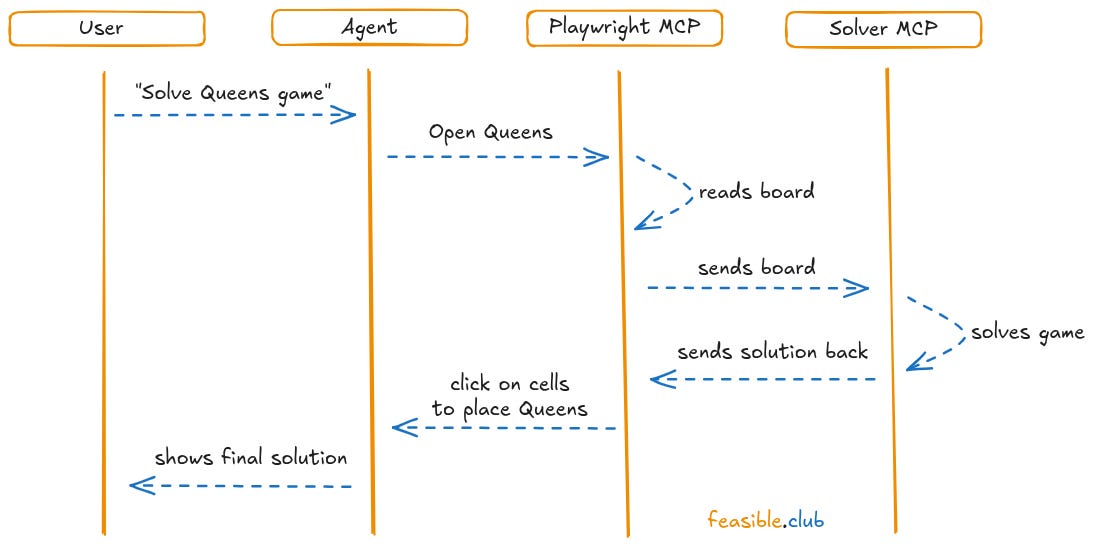
I built an AI agent that solved LinkedIn’s Queen game.
It opens the browser, reads the board, let a solver get the solution, and clicked on the board to actually solve it inside the game.
I didn’t plan to build that, just vibe-coded my way there.
And it worked pretty well.
In less than one hour, Claude Code did all the heavy lifting.
If AI can help us build things faster, what happens to how we do Operations Research? Is our way of coding going to change? And are there more implications to the field itself?
We talk a lot about AI replacing coding. But maybe what it’s really doing is changing how we think when we code.
Today in Feasible we’ll see:
👑 Building the LinkedIn’s Queens solver agent
📚 What I learned about GenAI for OR coding
🧩 What this means for my work (and maybe yours too)
Are you ready? Let’s dive in… 🪂

👑 Building the LinkedIn’s Queens solver agent
One hot August morning last year, I solved the Queens game automatically.
It was easy, but also not so automatic.
At that time, there was no Claude Code nor anything similar, and ChatGPT, while working pretty well, couldn’t handle everything by itself.
Thus I built something useful: a spreadsheet with a button to call a solver. You just needed to color the cells as in the game, put the initial Queens (if any), push the button, and you got the solution fast.
That’s still working, you can see all the info in this post and its comments.
But it felt kind of meh.
You needed to put a lot of effort by replicating the board in a spreadsheet, and after solving the game you needed to click into the board so to give the solution to LinkedIn.
I knew there had to be a better way. Since Claude Code had come, I started using it in my regular job, and I thought about replicating this by letting Claude Code actually code everything so that it’s solved automatically.
This is what I did.
The game is a variation of the well-known N-Queens problem in which you need to place N Queens in a board game of NxN squares so that none of them can attack each other. In this variation, you cannot place two Queens in the same row, nor in the same column, nor in the same color, nor touching them.
I asked Claude about how to leverage AI Agents with MCP (Model Context Protocol) servers to solve the game, and after a couple of messages it was clear I could:
Create an agent.
Let the agent explore the board game through Playwright to launch the web browser (as an MCP server).
Pass the board game to a solver (as an MCP server too).
Let the solver actually solve the game and return a solution.
Let the agent get that solution and click on the cells to place the Queens.
Then I went to Cursor (I was just testing it, you can use VSCode as you’re just using the agent’s terminal), gave some instructions to Claude about the context of the game, how I want it to solve it, the initial code that I already had because of the previous conversation, and the initial code I already had from the Google Sheet’s code I had one year ago.
🧠 Curious about the code?
You can explore the full implementation (Playwright + solver + agent logic) here (everything’s exactly as I vibe-coded it, didn’t touch a single line that Claude Code produced):
In a couple of minutes, it had everything in place: I could launch it and see how it went to the LinkedIn Queens’ page, get the board game, solve it and click on each position so that it gets solved. Like this:
It was slow: 5 minutes and 48 seconds for something I’d solve in just a minute? No way. What was happening here?
Just by looking at how the agent interacted with Playwright, I could easily see it was reading again and again the board to look for the specific cells to click twice (in fact, to click once, then look for the cell again, and click again).
That was a waste of time!
So I told it to improve that part and look for more improvements if there was any.
Its solution? Saving the board game in local (finding the important html parts), and caching the information in memory so it easily knows where to click.
After that, the agent could open the browser, read the board game, solve it and click for the solution in 1 minute and 2 seconds.
Not blazing, but good enough to prove two points:
Humans can orchestrate while AI explores.
Solvers fit naturally inside agent workflows.
Vibe-coding isn’t about coding faster but about extending our intuition and run experiments.
This was just that, one experiment, but a powerful one.
And I want to share with you if LLMs are good at coding for us or not, and what this means for OR practitioners like you and me.
This tiny puzzle became a testbed for a much bigger question: can LLMs really code for us, or are they just mimicking patterns?
📚 What I learned about GenAI for OR coding
This vibe-coding thing seems it worked for me, but am I just lucky or is this reproducible?
There has been multiple studies out there trying to decipher whether LLMs are good at coding or if they improve our productivity or not.
First things first, measuring productivity in developing environments is something really hard.
As an industry, sofware engineering has never found much consensus on many engineering practices, and there have always been teams able to outperform others by orders of magnitudes. So it feels just natural that, with AI as well, we have teams reporting wildly different outcomes.
This means that whatever your bias is about AI helping you (or not at all), you’ll get a study supporting it.
For example, you can read things like:
90% of our code is written by AI.
- Dan Shipper, founder of Every, on the Refactoring podcast.
But at the same time you can read some of the worst-looking numbers on AI productivity:
Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn’t.
- METR, in their randomized control trial.
And if we look at developer’s and modeler’s surveys as we did in a past post:
84% of Stack Overflow’s respondents are using or planning to use AI tools but 46% actively distrust accuracy. As we can see in Gurobi’s survey, only 6% of OR practitioners are actually using it, with 24% experimenting with it.
GenAI is everywhere in the conversation, but as you can see just 30% of people are actually doing something with it. Still less adoption than in general development environments.
The truth probably lies in the middle: AI coding tools make us faster at writing code, but not necessarily better at thinking through logic. And optimization is mostly logic.
Only 6% of OR practitioners are actually using AI tools, compared to 84% of general developers planning to. Why? Because our work isn’t about writing more code faster, it’s about reasoning through constraints, trade-offs, and feasibility. LLMs can generate syntax, but can they truly understand this constraint conflicts with that objective?
In the previous project, I vibe-coded everything, and even let ChatGPT one year ago to code everything for the spreadsheets’ solver.
But this project was more about how to let agents get information and pass it to a solver rather than actually coding a model/algorithm to solve a problem.
To me, using Claude Code (and probably other agents like Codex Cli) for coding tasks will give you a boost in productivity. I mean, I did let Claude Code manage everything, then I continue doing other things, and when I saw it somehow finished, tried it by myself and iterate again if needed.
It’s like I didn’t need to spend time on testing something I wanted to test (can we leverage agents to automate solving optimization problems?).
But I admit that optimization code might require a lot of reasoning about constraints and trade-offs.
In optimization, our bottleneck isn’t typing speed, it’s reasoning speed. And that’s exactly where AI shows both its brilliance and its blind spots.
As I already used Claude Code for helping me in that regard, let me tell you a couple of things in the next section.
🧩 What this means for my work (and maybe yours too)
Yes, I vibe-coded an entire thing without spending a lot of time actually coding.
It was more about giving context, my ideas, and how to connect the dots. Like I was just orchestrating Claude Code to actually do the job for me.
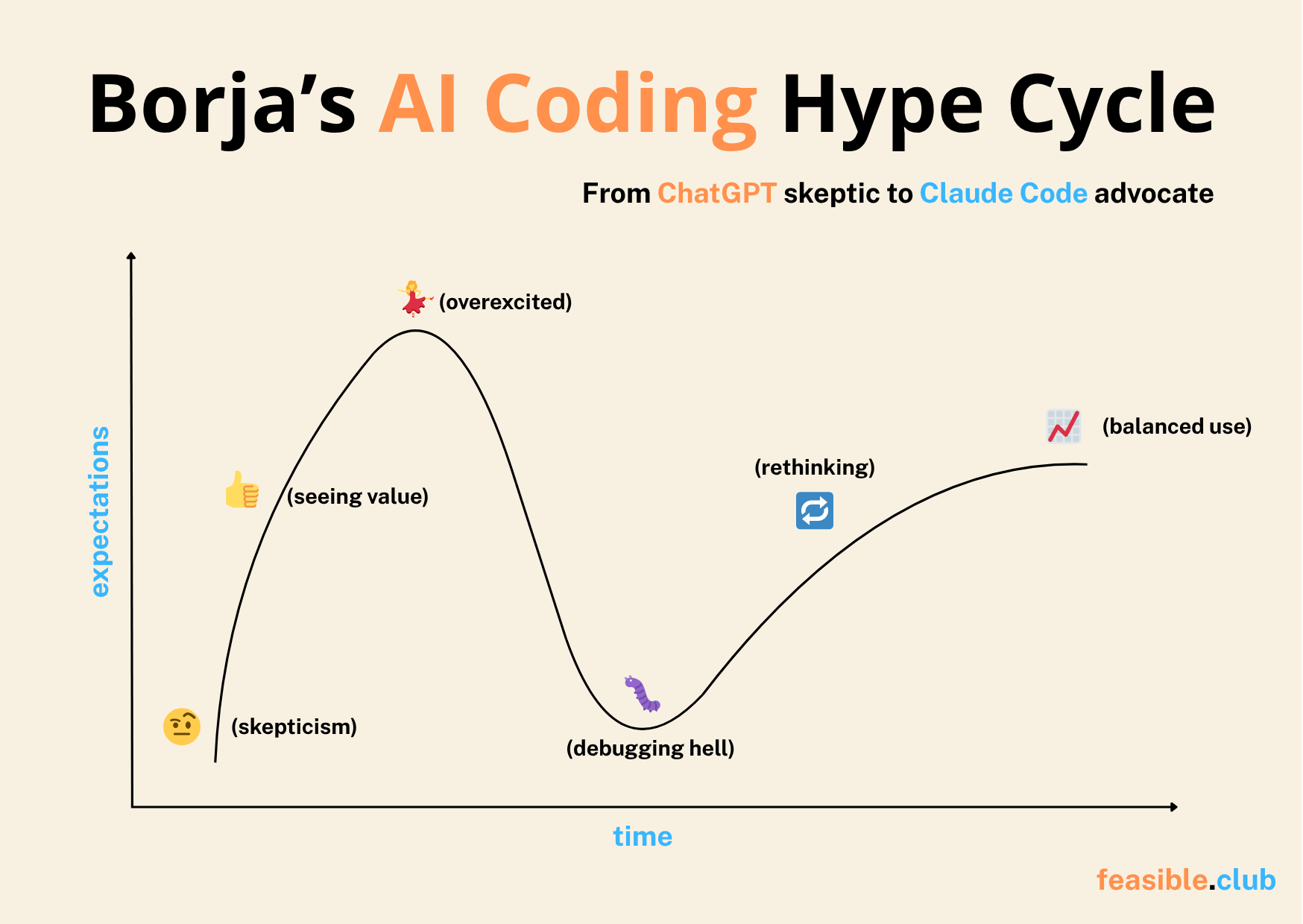
It all started some months ago, when I was skeptical about using AI to write my code. I tried it, and failed miserably. I thought AI would never be useful for coding.
At that point, I was just chatting with ChatGPT and/or Claude. It lacked enough context, so it couldn’t do its job well enough.
Then, I started to see its value. It was like “hey, it’s helpful; maybe not the best companion, but it gives you 80% of the code”. Not bad.
I gave better context to the chat, uploaded code, and some documents if I thought they were useful. The issue here is that it creates friction: you need to constantly update your code and documents to the chat project. But it can give you good results.
After that, I was so excited that I almost never read the code generated by AI. Just vibe coding. Tab, tab, tab. Apply, apply, apply. Run.
Then I moved to agents like Github Copilot coupled with GPT, Claude, or Gemini. It’s great as it has the context of the whole project (or at least a good summary of it), and lives inside VS Code, so the friction got removed. As a consequence, I applied more easily the changes done by the AI.
But I was disappointed. Debugging became #1 task. Also my #1 enemy. So much time and energy put here that I did a step back.
As a consequence of that ‘speed’ of coding, it created a lot of buggy code. The real problem is that as I didn’t audit the code that much, I spent more time debugging. And debugging code you didn’t write is a pain.
Finally, I looked at it with new eyes. If everyone was talking about it, “how come I couldn’t get barely any value from it?”. So I tried a different approach. And now with Claude Code, this is the approach I’m following:
Give Claude all the possible context I have so that I can understand if it understands everything well or if I lack giving it enough context.
Let it make a plan that I can edit if I think is not complete enough.
Let it code everything.
Everything looked like this:
As a note in the third point: I started by auditing every piece of code that it created. But the more I used it, the more I trusted it. So now I just audit all the changes it does at the end of the process.
But also: I don’t give it big tasks, just small ones -but big enough- that I know they’re needed for the project. That way, the agent can fully understand the tasks and increase the chances of doing it well.
Sometimes it gets cycled through the process of building something that fails, looking for the bug, trying to fix it, generate a different bug, trying to fix it, to get to the initial code.
When it happens, I stop using it and get my hands dirty. As I know what it did, it’s usually easy to catch the bug, but it could become hard if you don’t know what’s happening behind the scenes, so watch out: audit the code to understand it!
This way of working reflects a collaborative rhythm between human intuition and agent execution.
And I like it!
Optimization engineers like you might soon spend less time writing constraints, and more time deciding which problems are worth optimizing.
Agents aren’t replacing OR work, just changing the coding workflows. At least for now.
🏁 Conclusions
Today I wanted to show you how to leverage coding agents like Claude Code to automate workflows embedding a solver in a part of the chain.
I could easily do it, getting an agent that can get data from an external source (in this case, the web browser) and inputting that data into a solver to get a solution.
The whole system works pretty well, and this way of working lets you define the problem and ensure the solution makes sense in the real world:
Context first. Load notes, specs, sample data (when possible), and prior code until the agent can restate goals accurately.
Co-plan. Let the agent propose a plan; edit it to set scope and success checks.
Build small, ship small. Ask for self-contained increments (one tool, one interface, one test).
Audit at the end. Review the diff holistically; run tests; profile the hot path.
Break the loop. If it cycles bug→fix→new bug→new fix→old bug, take over, patch, and feed the fix back as context.
Now it becomes even more clear than ever that knowing what to build and how to evaluate it to increase trust in it will become much more important in the near future.
Today, AI can write and run the models we design. Tomorrow, agents might decide when and why to run them. That’s the next frontier.
That’s why next time, we’ll go one step further and explore what will happen with the OR field in this new context.
But for now, I’d love to know: how did you leverage Claude Code lately?
Let’s keep optimizing,
Borja.



